The Process & Philosophy Behind ‘Training Intelligent Machines’: AI (ML) Bots
Share :





We all must have heard about smart devices (e.g. smartphones) & intelligent machines or virtual assistants like Siri, Google Assistant, Cortana, Alexa, & AI-driven support bots on the internet. How come these simple abstract bunches of code are becoming so-called ‘intelligent’ or ‘smart’? The simplest of the answers could be—
“By allowing them to make mistakes & consolidating the lessons learned along the way!”
What is “intelligence” anyway?
As per the Oxford dictionary, “Intelligence is the ability to acquire and apply knowledge and skills.”
When we talk about ‘human intelligence’ or ‘IQ’, some might be of the view that it is quite relative & depends upon our ‘heredity’ or how intelligent our ancestors have been.
The academia negates this utopian view & as per the scientific studies “Intelligence” remains a matter of experience i.e. it depends on ‘continuous training’, ‘exposure’, ‘accepting challenges’ & ‘eradicating mistakes’ which in turn allows our brains to ‘re-wire’ its complex biological neural chain & gradually increase our IQ level.
Also Read: Dawn of a New Era with an Alloy of Artificial Intelligence and Mobile Application
A similar phenomenon applies to the field of artificial intelligent training machines where machines are turning more & more intelligent with each passing day. Their problem solving, pattern recognition, differentiation, logical reasoning, and calculated-decision-making skills are improving alongside aiming to touch the sky high human-level conscience.
But it is a way easier to be said than done.
In reality, we only have a partial understanding of the ‘process’ that goes underneath the complex chain of neural networks, either biological or artificial that results in a certain level of ‘IQ’ in humans or a certain level of ‘smartness’ in machines.
It’s more of a ‘natural outcome’ that shows up after an elongated period of training under countless diverse & adverse environmental conditions; consolidating the scenarios that are giving optimum results & eliminating the ones that are not.
AI/ML Bots ruling over the cyberspace
While browsing the internet, we knowingly or unknowingly come across AI/ML-based algorithmic bots that try to collect our data or manipulate our user-interface decisions as per the objectives defined for them. They frequently track our usage stats, browsing flow, & even local storage to comprehend our interests, our mood, preferences, needs, personal issues, or even paying potential.
The close enough examples could be Google Ads, Facebook suggestions, LinkedIn Ad campaigns, YouTube video recommendations or even the Amazon/ Flipkart product advertisements that we must have viewed on web-pages that are nowhere related to these websites.
For example, while booking airline tickets, we must have seen ‘dynamic price updations’ that may offer different prices to different sets of users at the same moment.
Apart from our usage statistics, all these scenarios depend upon the ‘digital-profiling’ done by these bots on us & how much ‘exploitable-potential’ a profile has.
The stock market trading on International stock exchanges, big financial transactions within multinational banks or even intelligence sharing among governments, all of them require hefty investments in the futuristic technologies like AI & ML for filtering out ‘fraudulent’ & ‘suspicious’ transactions among a dynamic list of gazillion financial transactions that could update within a fraction of a second.
Process of training intelligent machines (AI/ML) bots
In all the above examples, massive chunks of ‘user data sets’ & ‘financial data sets’ are exposed to these self-learning bots, which in turn are helping these bots to enhance their quality of future predictions based on the patterns in existing data.
Lately, humans were creating abstract algorithms with limitations on what could be achieved.
The initial bots were also trained using these abstract man-made instructions:
E.g. “IF <this> à THEN <that>”
To address the complexities that arose while solving large & complicated scenarios, this manual training process fell short in potential.
But with the advent of AI & ML, the complete cyberspace has taken a giant leap forward and the process of training these Algorithmic bots has been automated.
They don’t rely on humans to supervise or train them. Once their artificial neural structure (ANN) achieves a certain level of maturity, they start learning on their own when exposed to different training sets/ data sets. Meanwhile, the effort that goes into training a bot in its nascent stage can’t just be denied.
Unfortunately, these pieces of training are ‘highly guarded trade secrets’. But here we will try to make sense of these pieces of training, using a case study of our own.
Structure of Artificial Neural Network (ANN)
Let’s first get a birds-eye view of the input, processing, & output layers within an Artificial Neural Network that could also be considered a prototype to the biological human brain.
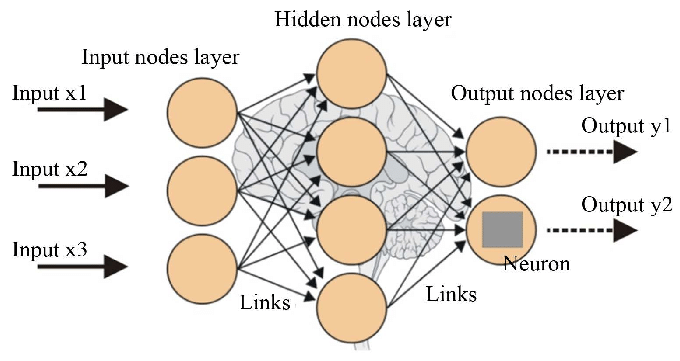
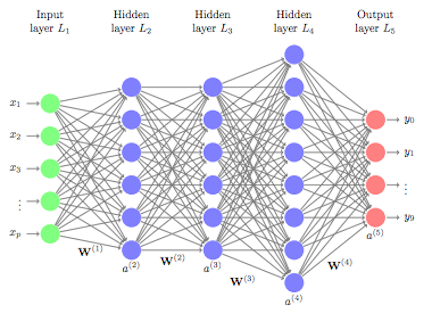
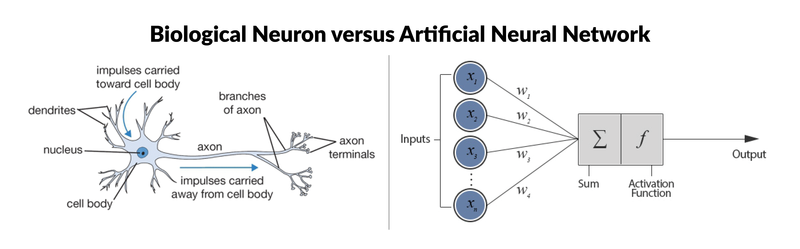
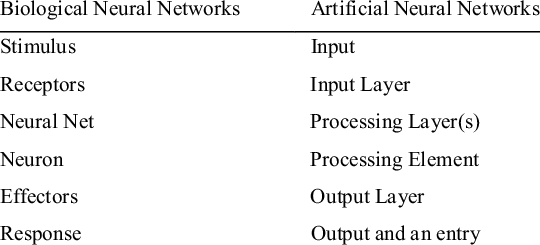
While academia is well aware of the working of an artificial/ biological neuron and how a cluster of neurons communicate with each other is vaguely grasped, detailing out the working of ‘complete package of neural wirings’ & ‘how a certain level of intelligence’ is achieved is still beyond scientific comprehension.
“Image-recognition”- A case study in AI/ML bots training
It is easier for humans (even children) to differentiate b/w two different objects by looking at their respective instances, e.g. say, the deformed images a dog & a bear.
This happens because wirings in our brain help us ‘relate’ the current visuals with memories of similar visuals & do the ‘memory-based pattern-recognition’.
We as humans have different shades of thought processes. Apart from memory-based learning we could relate, infer, assume, imagine, introspect, & innovate solutions that have never even existed before. Such cases are never perceived with machines/bots.
Their conditional programming makes them think linearly.
Therefore, in this scenario, it’s almost impossible for a bot to differentiate a dog & a bear by looking at their deformed images without incorporating AI/ML features into that bot.
This could only be achieved by incorporating ANN to bot’s programmable sets, creating infinite copies of that bot, & grilling all those bots through vast, rigorous, diverse, & indefinite ‘user-data sets/ training-sets’(e.g. Internet) that would allow them to make mistakes & re-wire their ANN.
In nascent stages, the tweaks made in their ANN would be manual & hence, more or less random. One can’t be sure if the individual modifications would result in an improved ‘image recognition’ skill or not.
Hence, an iterative ‘test-err-build-test’ cycle would be repeated indefinitely till a desired level of performance is attained by any of the bots. Let’s look into this training scenario.
“Test-Err-Build-Test-Repeat”: A intelligent machines training scenario for nascent bots
As we know that humans are unable to train a complex scenario to these bots. We would create two bots (say, a teacher bot & a builder bot) that would train a bunch of other bots (say, student bots). The ANN of these bots would be simpler and could easily be programmed by a human programmer.
At first, the wirings in student bot’s brains would be done at random & they are exposed to ‘training sets’ by Teacher-bot. The ‘training sets/ tests’ & ‘answer keys’ to each set is provided by the human overseer. The teacher bot ‘evaluates’ the tests under a controlled setup & maps the respective performances to each of the student bots.
These ML bots are then transferred to Builder-bot that sort out the best performers, creates multiple copies of them & does some non-calculated tweaks in their neural wiring intending to improve performance.
The bots are again transferred to Teacher-bot’s end that tests them with even harder training-sets. This ‘test-err-build-test’ cycle repeats indefinitely until a desired level of performance is achieved.
The success of this process also banks-on ‘discarding the under-performing bots’ and ‘re-wiring the top performers’ in each subsequent cycle. Furthermore, the human overseer is expected to keep the ‘bot’s-count’ & ‘training-sets/ user-data-sets’ as magnanimous as possible.
The initial performers would be lucky but with passing iterations & gradually increasing the complexity of ANN-wirings, the bots would incorporate ‘data-pattern-recognition’, ‘object-differentiation’, ‘logical reasoning’ & ‘calculated-decision-making’ skills depending on the nature of training sets they are exposed to.
E.g. In our case study, a bot is supposed to emerge who could successfully differentiate a dog & a bear even by looking at their deformed instances.
A real-life example similar to our case study is Google’s ‘image search algorithm’.
Intelligent Machines Training scenario for Mature enough ML bots
When these bots cross their nascent stage, they acquire an ability to learn on their own (similar to humans). Hence, from thereon, it becomes easier to deploy them over the internet where they would get continuous exposure to a large chunk of ‘user-data’/ ‘training sets’ and without the help of a human overseer or evaluator, they would self-assess & improve.
E.g. you must have come across ‘image-based captchas asking to identify a particular object (say, statues) among a bunch of other images before allowing you to access specific web content.
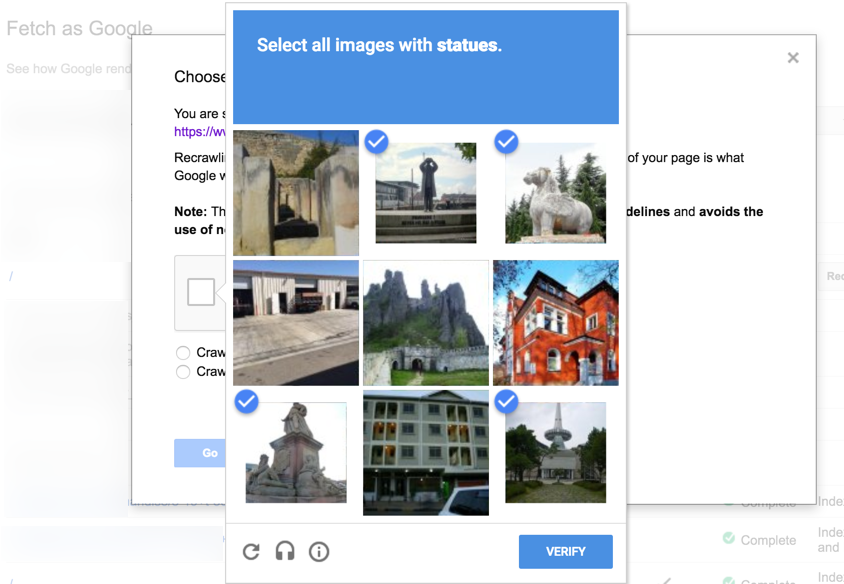
These captchas are covertly acting as training sets & helping these bots develop their object differentiation & image recognition skills.
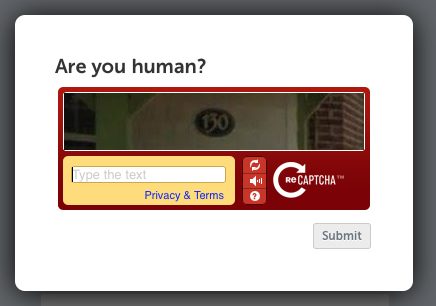
Other such examples include “Are you human?” or “Confirm you are not a robot” kinds of tests that are helping such bots learn how to read & count.

Tests on the social media sites like “pick the photos of your friends that are most likable, or choose the articles that have been shared the most”, all have this covert objective that goes behind the scenes.
The more such user-data these bots would be exposed to, the better their humanistic-skills would shape up.
This is the reason why big corporates are obsessed with collecting user-data these days.
The dark side of intelligent training machines: Data Privacy issue
There is also a contrasting side of all we have gone through.
Countries nowadays are becoming more & more overprotective about their citizens’/user’s data privacy, the reason being the malpractices that go into training these bots to manipulate user’s interaction on the internet in such a way that they can’t be termed legitimate.
For instance, Cambridge Analytica’s case in which Facebook & Twitter were tracking their user’s tweets, posts, & activities without even their consent, which was later found to be used in manipulating the overall mood of people before the USA’s presidential elections of 2015.
Conclusion
AI/ML is the most fascinating field for the entire academia. Not just because a slight glimpse of it is showcasing immense possibilities for the future, but also because it’s a quest to create ‘ourselves’. To create our own-selves, it is pre-requisite to ‘understand’ our own-selves & this is where the trick lies.
Concluding this blog with a simple question,
“If AI is a quest to create consciousness, how come an unconscious being is going to create a conscious machine?”
-
 How Much Does it Cost to Build an MVP App in 2024?
How Much Does it Cost to Build an MVP App in 2024? -
How Does E-Commerce App Development Help Retailers With Their Problems in the Retail Industry?
-
How AI is Changing the Landscape of the Online Food Delivery Industry?


